Help
1.What is GETdb?
2.Data sources and tools for analyses.
3.Pipeline to construct GETdb.
4.Collection and processing of genetic features for drug targets.
5.Collection of evolutionary features for drug targets.
6.Collection of basic biological features for drug targets.
7.Construction of allosteric protein prediction model.
8.GETdb guidelines.
9.Search interface of GETdb.
10.Browse interface of GETdb.
11. Laboratory Introduction.
1.What is GETdb?
GETdb not only integrates and standardizes data from dozens of commonly used drug and target databases, but also innovatively includes the genetic and evolutionary information of targets. Moreover, considering that allosteric proteins have great potential as targets due to their structural diversity, this database is also equipped with an effective allosteric protein prediction model.
In GETdb, users can:
1. Query the genetic and evolutionary information of genes
2. Query the basic biomedical information of genes
3. Query the targeted genes and clinical information of drugs
4. Query the associated genes/proteins and drugs of diseases
5. Prediction the allosteric proteins
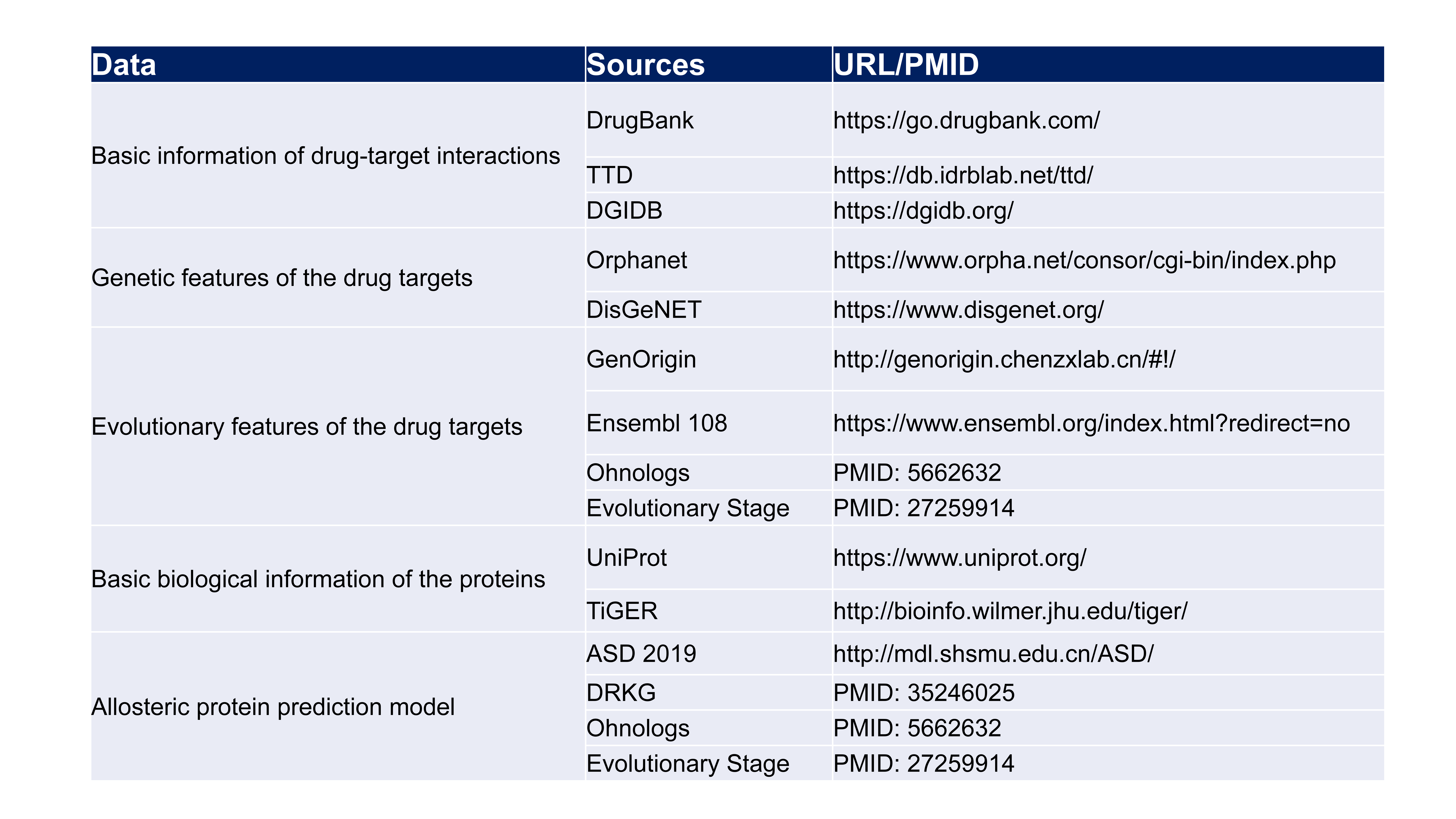
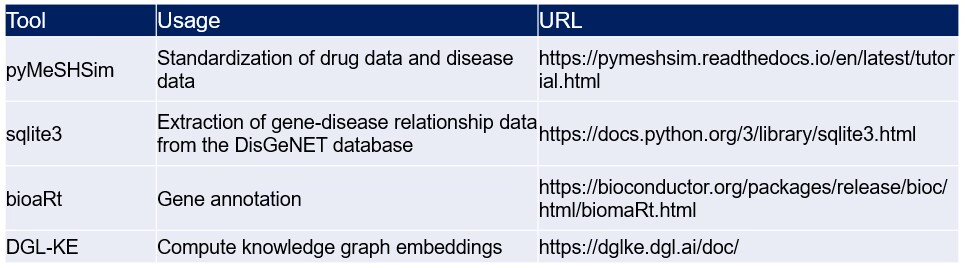
2.Data sources and tools for analyses.
3.Pipeline to construct GETdb.
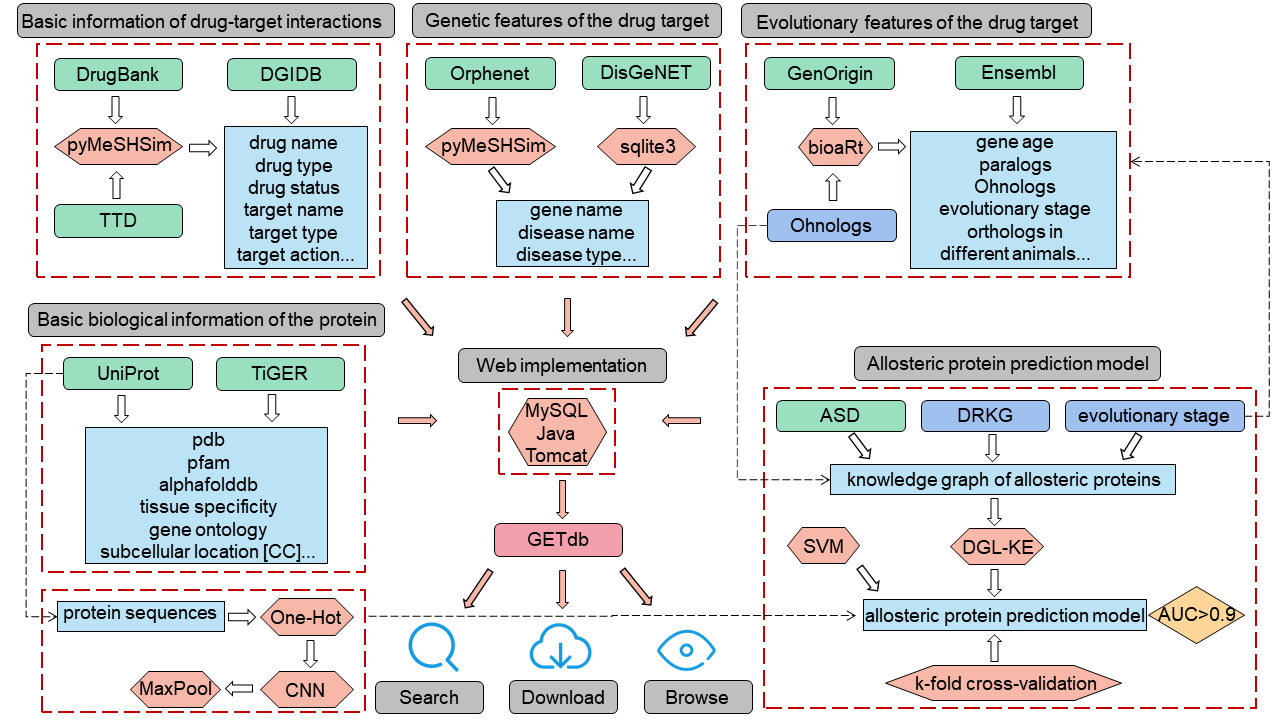
4.Collection and processing of genetic features for drug targets.
The disease descriptions from diverse data sources were standardized utilizing the Unified Medical Language System (UMLS) to ensure consistency in disease names and to mitigate potential confusion arising from synonyms, abbreviations, and other variations. The standardization process was performed using PyMeSHSim. Subsequently, the two gene-disease datasets were merged based on the CUI identifier (a unique concept identifier in the UMLS) and gene names, with an additional column labeled as "source" appended to indicate the respective data sources.
5.Collection of evolutionary features for drug targets.
Information on the evolutionary stage of the target, the age of the target, Ohnologs, orthologs, paralogs, and phenotypic similarity of orthologous genes between humans and mice were collected as evolutionary features of the drug target. Liebeskind et al. have inferred the age of genes based on 13 popular homology inference algorithms and classified human genes into eight major categories. This information on the stage of origin was added to our database to further understand the function and disease relevance of genes. The age of a gene is strongly correlated with its function and also with human disease, and to gain a clearer understanding of the evolutionary features of drug targets, we downloaded age information of human protein-coding genes from GenOrigin (http://genorigin.chenzxlab.cn/#!/). Duplicate Ohnologs generated during whole genome duplication (WGD) events have been shown to be metrologically sensitive and a potential source of drug candidates, and the information was therefore incorporated into our database construction. In addition, Orthologs are formed by species evolution and paralogs are often functionally similar. We collected information on paralogous genes and orthologous genes across multiple species including Alpaca (Vicugna pacos), Chimpanzee (Pan troglodytes), Dog (Canis lupus familiaris), Guinea Pig (Cavia porcellus), Macaque (Macaca), Mouse (Mus musculus), Pig (Sus scrofa), Rat (Rattus norvegicus), and Rabbit (Oryctolagus cuniculus) from Ensembl 108 (https://www.ensembl.org/index.html?redirect=no). Although the sequences of orthologous genes are highly conserved, functional divergence between orthologous gene products frequently occurs during evolution. Doyeon Ha et al. conducted evolutionary rewiring of regulatory networks and identified 642 high-phenotype-similarity genes and 642 low-phenotype-similarity genes based on phenotype similarity (PS) scores. These genes were used to explain the phenotypic differences between orthologous genes in humans and mice. The data have been integrated into our database for target discovery purposes.
6.Collection of basic biological features for drug targets.
It has been shown that genes with tissue specificity are twice as likely to be targets as common genes, which would facilitate the discovery of new therapeutic targets, and we have collected tissue-specific information on human genes from Tissue-specific Gene Expression and Regulation (TiGER) (http://bioinfo.wilmer.jhu.edu/tiger/). To gather essential biological features of drug targets, we collected information from UniProt database (accessed September 2022), including Gene Ontology (GO) annotations, single nucleotide polymorphism (SNP) data, motif information, subcellular localization details, as well as Protein Data Bank (PDB) and Pfam entry identifiers. The GO information provided insights into the functional annotations of the target proteins, categorizing them into molecular function, biological process, and cellular component. SNP data allowed us to analyze the impact of genetic variations on protein function and phenotype. Motif information aided in identifying specific sequence patterns associated with functional regions. Subcellular localization details shed light on the intracellular distribution of the target proteins. Furthermore, the inclusion of PDB and Pfam entry identifiers facilitated direct access to corresponding three-dimensional protein structures and conserved domains. These comprehensive datasets were integrated into our study. The AlloSteric Database (ASD 2019) (http://mdl.shsmu.edu.cn/ASD/) serves as a repository for a substantial collection of experimentally validated or reported allosteric proteins. Within our GETdb, we have incorporated information on 837 allosteric proteins associated with humans, sourced from the ASD database.
7.Construction of allosteric protein prediction model.
Ohnologs and evolutionary stage information were incorporated into the primary KG to construct an evolutionary-enhanced KG, and the feature vectors for histone protein entities were re-extracted. For the primary KG and the evolutionary-enhanced KG, we used the TransE_l2 algorithm to represent all entities and relationships as a 400-dimensional vector. The allosteric proteins present in KG and ASD were employed as positive samples for the machine learning model, while an equivalent number of non-allosteric proteins from the protein entity collection were selected at random as negative samples. The training dataset thus assembled comprised 1642 samples, and the protein features derived from the primary KG were subjected to support vector machine (SVM) modeling, denominated as "Primary Model". The traits extracted from the evolutionary-enhanced KG were combined with protein sequence features, resulting in a 560-dimensional vector. These traits were subsequently utilized as input to the SVM algorithm for the construction of a model denominated as "Evolutionary-enhanced Model". The construction process was identical to that employed for "Primary Model". In order to optimize the utility of the data, we adopted a 3-fold cross-validation approach for the training of the classifier, which was repeated 200 times to enhance the stability of the outcomes. The performance of the classifier was assessed through the computation of the area under the curve (AUC) of the receiver operating characteristic (ROC) curve, which generally reflects the efficacy of the model. Accuracy, error rate, recall, and ROC values were utilized as evaluation criteria for comparing different models. The optimal model was then employed to generate predictions for all proteins in KG, and these predictions, including the output decision values and variability status, were recorded in GETdb.
8.GETdb guidelines.
To effectively utilize the information provided by GETdb for selecting drug targets, researchers should follow these concise steps:
1. ** Focus on Closely Related Genes ** : Select genes that are closely associated with disease phenotypes.
2. ** Evolutionary Features Assessment ** : Choose genes at key evolutionary stages (cellular organisms, Eukarya+Bacteria, Eumetazoa, Vertebrata), with Ohnolog genes having a higher probability of being successful targets.
3. ** Consider Allosteric Potential ** : Utilize prediction models for allosteric proteins to select targets that play a crucial role in cellular function , offering advantages like high specificity and low drug resistance.
4. ** Tissue Specificity Consideration ** : Based on the tissue specificity of targets, select those acting on appropriate sites to optimize therapeutic effects and minimize side effects.
5. ** Model Organism Selection ** : Choose suitable model organisms for target testing based on homologous genes to verify the efficacy and safety of the targets.
Following these guidelines, researchers can more accurately identify and validate potential therapeutic targets, facilitating the development of more effective and safer drugs.
9.Search interface of GETdb.

10.Browse interface of GETdb.
11.Laboratory Introduction.

> Drug discovery
> Drug target identification
> Pathogenesis interpretation of diseases
Yuan Quan, Ph.D. Associate Professor
quanyuan@mail.hzau.edu.cn
Hong-Yu Zhang, Ph.D. Professor
zhy630@mail.hzau.edu.cn
Yang He, M.S.
he_yang@webmail.hzau.edu.cn
Qi Zhang, M.S.
qzhang@webmail.hzau.edu.cn